matplotlib 可视化总结
之前的几期中,我们推出了python语法和pandas数据处理的模块,这是用来做数据分析最不可或缺的技能。今天我们接着推出matplotlib可视化的模块。可视化也是在整个数据分析流程中必不可少的一个环节,因为图形远比单纯的数字易于理解和接受,一个好的可视化图形能够“不言自明”,给听众留下深刻的印象。这一期推出的matplotlib模块,是python中应用最为广泛的一个可视化工具包,它可以对整个可视化的图形进行“雕刻”,让图形满足我们表达信息,传递信息的需要。
做可视化工作需要分成以下三个阶段:
- 数据准备:将需要进行可视化的数据进行处理,如异常值的处理,以及数据格式转化等(Pandas 处理过程)
- 数据类型:数值型数据 or 分类型数据
- 数据异常:取值异常 or 数据缺失
- 确定图表:思考需要用什么图来分析比较合适,不同的目的所需要的图表也不同。
- 关联分析:散点图或折线图。观察两个变量之间的相关关系
- 分布分析:柱状图,密度图。观察数据的分布
- 分类分析:柱状图或箱式图。按类别进行分析
- 分析输出结论:这也是做可视化的目的,是可视化最重要的一步。对可视化的图形进行分析,得出结论,一般而言,这种结论是直接观察数据不易发现的结论。
对于matplotlib这个模块来说,由于涉及到的内容太多,因此要从实践,从需求出发,不适合按照知识点的模式进行学习,采用“用中学”的方法能够极大的提高学习效率。在这个模块中,我们会以几个简单的案例来对matplotlib常用的命令进行说明,主要目的是利用这几个简单案例将基本常用的操作命令都用到,因此不追求案例的新颖性。
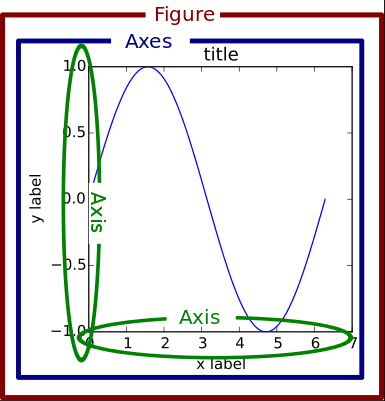
在开展具体的案例之前,我们先抛出一张在matplotlib中各个对象名称的图片,这对大家理解非常有帮助,在后边文章中遇到不理解的可以参考这张图片。
案例一:航班乘客分析
在另一个可视化模块seaborn中,我们可以直接从网络上下载数据集,因此不用自己准备数据来练习matplotlib操作。
在打算利用matplotlib作图之前,一般需要导入以下包。
import matplotlib as mpl
from matplotlib import pyplot as plt
import pandas as pd
#这一行很重要,只有写了这一行代码,可视化后的图形才能在notebook中展现出来
%matplotlib inline
加载需要用到的数据集并进行展示。
#导入seaborn包
import seaborn as sns
#加载数据集
data = sns.load_dataset('flights')
data.head()

可以看出这份数据包含了年份(1949 - 1960),月份,乘客数量三列数据。
我们想通过这份数据来分析一下乘客数量的年度变化情况和月度变化情况。当需要对一个问题进行分析时,首先要确定用什么样的图表来展现比较合适,很明显,这个问题用折线图或者柱状图来展现比较合适。
可以发现,分析年度变化情况或者月度变化情况,我们不能直接用原始数据进行画图,首先需要进行一下分类汇总。
amount_per_year = data.groupby("year")[['passengers']].sum()
amount_per_year.head()

这时,amount_per_year对年度数据进行了汇总。可以利用amount_per_year的数据进行可视化。每个命令的含义和使用方法都在注释中。因为matplotlib的知识点超级多,想要系统的学习完是不可能的,而且也是不正确的学习方法,还是要坚持在用中学,不断积累基本用法,这样才能够不断的熟悉,操作越来越得心应手。
#定义一张画布,确定画布的大小
fig = plt.figure(figsize = (14,7))
#确定折线图的横纵轴的数据
x = amount_per_year.index
y = amount_per_year['passenger']
#用plt.plot()来绘制折线图,'g--'表示绿色,线型为虚线,label表示图例的内容
plt.plot(x,y,'g--',label = 'passenger number')
#plt.legend()可以对图例的位置和大小进行设置
plt.legend(loc = 'upper left',fontsize = 'large' )
#设置整个图片的标题
plt.title('passenger number via year')
#设置x轴名称
plt.xlabel('year')
#设置y轴名称
plt.ylabel('passenger number')
plt.show()

从图形中可以看出,在1949年到1960年间,乘客的数量是逐年递增的。
接下来分析月度乘客数量的变化。
amount_per_month = data.groupby("month")[['passengers']].sum()
amount_per_month

#更改索引值,将月份值改为数字,若不改为数字,横坐标会按照月份英文的首字母进行排序
amount_per_month.index = np.arange(1,13,1)
#定义一张画布,并设置画布大小
fig = plt.figure(figsize=(10,5))
#确定x,y的值
x1 = amount_per_month.index
y1 = amount_per_month["passengers"]
#画柱状图,设置每个柱子的颜色,还有宽度
plt.bar(x1,y1,color = "cyan",width = 0.6)
plt.xlabel("month")
plt.ylabel("passengers number")
plt.title("passengers per month")
plt.show()

从这个图中可以明显的看出7月和8月份的出行人数最多。这个分析过程也可以使用折线图来完成,这里使用柱状图是为了使大家能够熟悉不同种类图形的绘制方法。
鸢尾花数据集分析
主要分析以下三个问题,这个数据集是一个公开数据集,其本身并没有很大的实用意义,我们使用这个数据集主要是为了熟悉matplotlib的常用操作。
- 萼片(sepal)和花瓣(petal)的大小关系(散点图)
- 不同种类(species)鸢尾花萼片和花瓣的大小关系(分类散点子图)
- 不同种类鸢尾花萼片和花瓣大小的分布情况(直方图或者箱式图)
萼片(sepal)和花瓣(petal)的大小关系
首先导入数据集,我们可以明显看出这个问题在于分析两个变量之间的关系,因此适宜用散点图来进行分析。散点图的作用就在于能够直观判断不同变量之间的相关关系。
data = sns.load_dataset("iris")
data.head()
# 萼片长度,萼片宽度,花瓣长度,花瓣宽度,种类

要分析萼片和花瓣的大小关系,需要先计算以下两者的尺寸,用各自的长乘各自的宽。这里也提醒我们一点,在数据分析过程中,拿到原始数据后,可以利用其中的某些特征自己组合新的特征来进行分析,实践也证明这种组合特征往往能够带来很多意外的惊喜。
# 计算sepal和petal的大小,进行数据准备
data["sepal_size"] = data["sepal_length"] * data["sepal_width"]
data["petal_size"] = data["petal_length"] * data["petal_width"]
data.head()

# 准备一张画布和作图区域
fig,axes = plt.subplots(figsize = (10,5))
# 绘制散点图,alpha是透明度
axes.scatter(data['sepal_size'],data['petal_size'],alpha = 0.8,color = "red")
# 设置x轴和y轴标签
axes.set_xlabel("sepal_size")
axes.set_ylabel('petal_size')

从散点图上看不出这两个变量之间存在着明显的相关关系。
不同种类(species)鸢尾花萼片和花瓣的大小关系
接下来分析不同种类(species)鸢尾花萼片和花瓣的大小关系,因为一共有三类鸢尾花,因此这个问题需要用分类散点子图来画。
#准备一张画布
plt.figure(figsize = (14,7))
#确定画图的位置
place = 1
for species in data['species'].unique():
#分别得出散点图的横纵坐标轴的值,利用pandas来进行筛选操作
sepal_size = data[data["species"] == species]['sepal_size'].values
petal_size = data[data["species"] == species]['petal_size'].values
#在相应的位置上画图
plt.subplot(2,2,place)
#绘制散点图,可以设置点的形状,大小等参数
plt.scatter(sepal_size,petal_size)
plt.xlabel(species + " sepal_size")
plt.ylabel(species +" petal_size")
#更改作图位置
place = place + 1
plt.show()

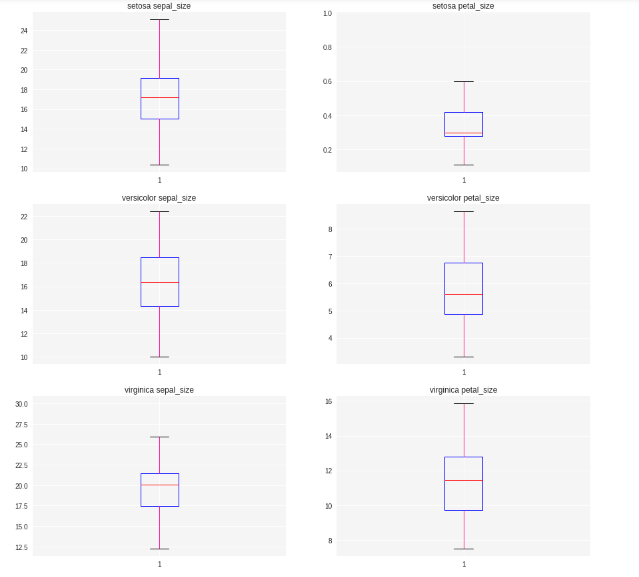
不同种类鸢尾花萼片和花瓣大小的分布情况
首先,当我们分析这个问题时,明确是要分析某个特征的分布情况,一般这种情况下,使用直方图或者箱式图最合适不过了。在这里我们选择箱式图来进行可视化。和上边的例子一样,我们先把代码放在下边,配以详细的注释说明,边读注释,边理解代码。
# 绘制箱式图,箱式图需要分别绘制三种鸢尾花的sepal_size和petal_size,共六个图
# 准备一张画布
plt.figure(figsize = (15,15))
# 确定画每张子图的位置,初始化为1
place = 1
#进行循环来画每张子图
for species in m.index:
#分别得出散点图的横纵坐标轴的值,再一次强调,一定要熟练使用pandas!!!
sepal_size = data[data["species"] == species]['sepal_size']
petal_size = data[data["species"] == species]['petal_size']
#绘制每种鸢尾花的sepal_size
#在相应的位置上画图,3行2列共六个作图位置,place参数表示具体画图的位置
plt.subplot(3,2,place)
#绘制箱式图,medianprops表示中位数那条线的属性,boxprops表示箱子的属性
plt.boxplot(sepal_size.values,
medianprops = {'color':"red"},
boxprops = {'color' : "blue"},
whiskerprops = {"color" : "deeppink"})
#添加标题
plt.title(species + " sepal_size")
# 绘制每种鸢尾花的petal_size
plt.subplot(3,2,place + 1)
#绘制箱式图
plt.boxplot(petal_size.values,
medianprops = {'color':"red"},
boxprops = {'color' : "blue"},
whiskerprops = {"color" : "deeppink"})
plt.title(species + " petal_size")
# 画图位置进行迭代
place = place + 2 #更改作图位置
plt.show()
-
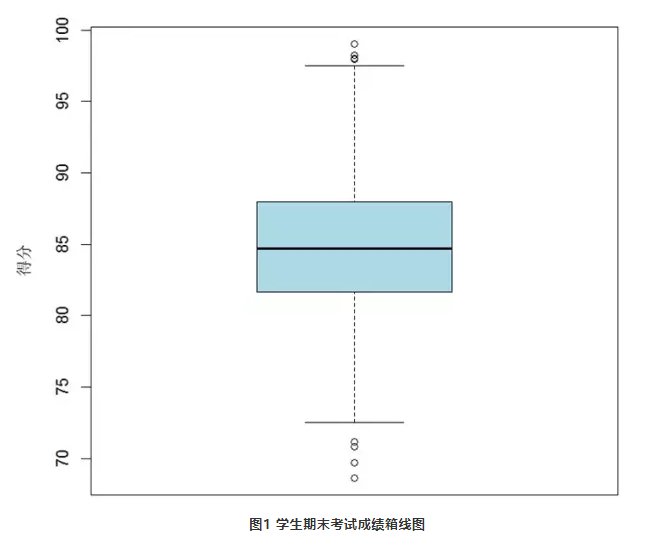
箱式图的介绍 参考狗熊会:丑图百讲
先看一张标准的箱式图。箱子的中间一条线,是数据的中位数,代表了样本数据的平均水平。
箱子的上下限,分别是数据的上四分位数和下四分位数。这意味着箱子包含了50%的数据。因此,箱子的宽度在一定程度上反映了数据的波动程度。
在箱子的上方和下方,又各有一条线。有时候代表着最大最小值,有时候会有一些点“冒出去”。请千万不要纠结,不要纠结,不要纠结(重要的事情说三遍),如果有点冒出去,理解成“异常值”就好。
- 箱式图是针对连续型变量的,解读的时候重点关注平均水平,波动程度和异常值。直方图是针对离散性变量的。
- 当箱子被压的很扁或者有很多异常值的时候,试着做对数变换。
- 当只有一个连续型变量时,并不适合画箱线图,直方图是更常见的选择。
- 箱线图最有效的使用途径是作比较,配合一个或者多个定性数据,画分组箱线图。
关于matplotlib的介绍就这些了,欢迎大家提出问题一起学习。我们有对应的微信公众号“数据跬步”,欢迎大家关注。有问题可以直接在微信后交流,这种方式效率会更高一些。
